Update: Fixed feedback link.
The Rough Cut of Hadoop: The Definitive Guide is now up on O'Reilly's site. There are a few chapters available already, at various stages of completion. Remember, it's still pretty rough. I'd love to hear any suggestions for improvements that you may have though. You can submit feedback from Safari where the book is hosted. As the Rough Cuts FAQ explains, I'd like feedback on missing topics, if something is not understandable, and technical mistakes.
Now I just need to go and write the rest of it...
Tuesday, 16 September 2008
Thursday, 4 September 2008
Hosting Large Public Datasets on Amazon S3
Update: I just thought of a quick and dirty way of doing this: just store your content on an extra large EC2 instance (holds up to 1690GB) and make the image public. Anyone can access it using their EC2 account, you just get charged for hosting the image.
There's a great deal of interest in large, publicly available datasets (see, for example, this thread from theinfo.org), but for very large datasets it is still expensive to provide the bandwidth to distribute them. Imagine if you could get your hands on the data from a large web crawl, the kind of thing that the Internet Archive produces. I'm sure people would discover some interesting things from it.
Amazon S3 is an obvious choice for storing data for public consumption, but while the cost for storage may be reasonable, the cost for transfer can be crippling since the cost is not under the control of the data provider, being incurred for each transfer (which is initiated by the user).
For example, consider a 1TB dataset. With storage running at $0.15 per GB per month this works out at around $150 per month to host. With transfer costs costing $0.18 per GB, this dataset costs around $180 for each transfer out of Amazon! It's not surprising large datasets are not publicly hosted on S3.
However, transferring data between S3 and EC2 is free, so could we limit transfers from S3 so they are only possible to EC2? You (or anyone else) could run an analysis on EC2 (using Hadoop, say) and only pay for the EC2 time. Or you could transfer it out of EC2 at your own expense. S3 doesn't support this option directly, but it is possible to emulate it with a bit of code.
The idea (suggested by Doug Cutting) is to make objects private on S3 to restrict access generally, then run a proxy on EC2 that is authorized to access the objects. The proxy only accepts connections from within EC2: any client that is outside Amazon's cloud is firewalled out. This combination ensures only EC2 instances can access the S3 objects, thus removing any bandwidth costs.
A few questions:
There's a great deal of interest in large, publicly available datasets (see, for example, this thread from theinfo.org), but for very large datasets it is still expensive to provide the bandwidth to distribute them. Imagine if you could get your hands on the data from a large web crawl, the kind of thing that the Internet Archive produces. I'm sure people would discover some interesting things from it.
Amazon S3 is an obvious choice for storing data for public consumption, but while the cost for storage may be reasonable, the cost for transfer can be crippling since the cost is not under the control of the data provider, being incurred for each transfer (which is initiated by the user).
For example, consider a 1TB dataset. With storage running at $0.15 per GB per month this works out at around $150 per month to host. With transfer costs costing $0.18 per GB, this dataset costs around $180 for each transfer out of Amazon! It's not surprising large datasets are not publicly hosted on S3.
However, transferring data between S3 and EC2 is free, so could we limit transfers from S3 so they are only possible to EC2? You (or anyone else) could run an analysis on EC2 (using Hadoop, say) and only pay for the EC2 time. Or you could transfer it out of EC2 at your own expense. S3 doesn't support this option directly, but it is possible to emulate it with a bit of code.
The idea (suggested by Doug Cutting) is to make objects private on S3 to restrict access generally, then run a proxy on EC2 that is authorized to access the objects. The proxy only accepts connections from within EC2: any client that is outside Amazon's cloud is firewalled out. This combination ensures only EC2 instances can access the S3 objects, thus removing any bandwidth costs.
Implementation
I've written such a proxy. It's a Java servlet that uses the JetS3t library to add the correct Amazon S3Authorization HTTP header to gain access to the owner's objects on S3. If the proxy is running on the EC2 instance with hostname ec2-67-202-43-67.compute-1.amazonaws.com, for example, then a request forhttp://ec2-67-202-43-67.compute-1.amazonaws.com/bucket/objectis proxied to the protected object at
http://s3.amazonaws.com/bucket/objectTo ensure that only clients on EC2 can get access to the proxy I set up an EC2 security group (which limits access to port 80):
ec2-add-group ec2-private-subnet -d "Group for all Amazon EC2 instances."Then by launching the proxy in this group, only machines on EC2 can connect. (Initially, I thought I had to add public IP addresses to the group -- which, incidentally, I found in this forum posting -- but this is not necessary as the public DNS name of an EC2 instance resolves to the private IP address within EC2.) The AWS credentials to gain access to the S3 objects are passed in the user data, along with the hostname of S3:
ec2-authorize ec2-private-subnet -p 80 -s 10.0.0.0/8
ec2-run-instances -k gsg-keypair -g ec2-private-subnet \This AMI (ID
-d "<aws_access_key> <aws_secret_key> s3.amazonaws.com" ami-fffd1996
ami-fffd1996) is publicly available, so anyone can use it by using the commands shown here. (The code is available here, under an Apache 2.0 license, but you don't need this if you only intend to run or use a proxy.)Demo
Here's a resource on S3 that is protected: http://s3.amazonaws.com/tiling/private.txt. When you try to retrieve it you get an authorization error:% curl http://s3.amazonaws.com/tiling/private.txtWith a proxy running, I still can't retrieve the resource via the proxy from outside EC2. It just times out due to the firewall rule:
<?xml version="1.0" encoding="UTF-8"?>
<Error>
<Code>AccessDenied</Code>
<Message>Access Denied</Message>
<RequestId>57E370CDDD9FE044</RequestId>
<HostId>dA+9II1dYAjPE5aNsnRxhVoQ5qy3KCa6frkLg3SyTwzP3i2SQNCU534/v8NXXEnN</HostId>
</Error>
% curl http://ec2-67-202-56-11.compute-1.amazonaws.com/tiling/private.txtBut it does works from an EC2 machine (any EC2 machine):
curl: (7) couldn't connect to host
% curl http://ec2-67-202-56-11.compute-1.amazonaws.com/tiling/private.txt
secret
Conclusion
By running a proxy on EC2, at 10 cents per hour (small instance) - or $72 a month, you can allow folks using EC2 to access your data on S3 for free. While running the proxy is not free, it is a fixed cost that might be acceptable to some organizations, particularly those that have an interest in making data publicly available (but can't stomach large bandwidth costs).A few questions:
- Is this useful?
- Is there a better way of doing it?
- Can we have this built into S3 (please, Amazon)?
Saturday, 23 August 2008
Elastic Hadoop Clusters with Amazon's Elastic Block Store
I gave a talk on Tuesday at the first Hadoop User Group UK about Hadoop and Amazon Web services - how and why you can run Hadoop with AWS. I mentioned how integrating Hadoop with Amazon's "Persistent local storage", which Werner Vogels had pre-announced in April, would be a great feature to have to enable truly elastic Hadoop clusters that you could stop and start on demand.
Well, the very next day Amazon launched this service, called Elastic Block Store (EBS). So in this post I thought I'd sketch out how an elastic Hadoop might work.
A bit of background. Currently there are three main ways to use Hadoop with AWS:
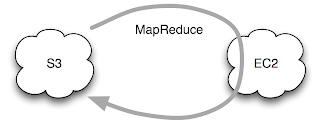 In this set up, the data resides on S3, and the MapReduce daemons run on a temporary EC2 cluster for the duration of the job run. This works, and is especially convenient if you've already store your data on S3, but you don't get any data locality. Data locality is what enables the magic of MapReduce to work efficiently - the computation is scheduled to run on the machine where the data is stored, so you get huge savings in not having to ship terabytes of data around the network. EC2 does not share nodes with S3 storage, in fact they are often in different data centres, so performance is nowhere near as good as a regular Hadoop cluster where the data in stored in HDFS (see 3. below).
In this set up, the data resides on S3, and the MapReduce daemons run on a temporary EC2 cluster for the duration of the job run. This works, and is especially convenient if you've already store your data on S3, but you don't get any data locality. Data locality is what enables the magic of MapReduce to work efficiently - the computation is scheduled to run on the machine where the data is stored, so you get huge savings in not having to ship terabytes of data around the network. EC2 does not share nodes with S3 storage, in fact they are often in different data centres, so performance is nowhere near as good as a regular Hadoop cluster where the data in stored in HDFS (see 3. below).
It's not all doom and gloom, as the bandwidth between EC2 and S3 is actually pretty good, as Rightscale found when they did some measurements.
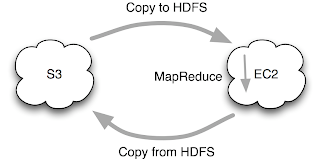 Data is stored on S3 but copied to a temporary HDFS cluster running on EC2. This is just a variation of the previous set-up, which is good if you want to run several jobs against the same input data. You save by only copying the data across the network once, but you pay a little more due to HDFS replication.
Data is stored on S3 but copied to a temporary HDFS cluster running on EC2. This is just a variation of the previous set-up, which is good if you want to run several jobs against the same input data. You save by only copying the data across the network once, but you pay a little more due to HDFS replication.
The bottleneck is still copying the data out of S3. (Copying the results back into S3 isn't usually as bad as the output is often an order or two of magnitude smaller than the input.)
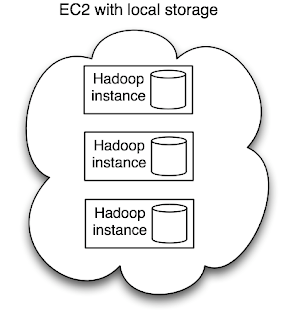 Of course, you could just run a Hadoop cluster on EC2 and store your data there (and not in S3). In this scenario, you are committed to running your EC2 cluster long term, which can prove expensive, although the locality is excellent.
Of course, you could just run a Hadoop cluster on EC2 and store your data there (and not in S3). In this scenario, you are committed to running your EC2 cluster long term, which can prove expensive, although the locality is excellent.
These three scenarios demonstrate that you pay for locality. However, there is a gulf between S3 and local disks that EBS fills nicely. EBS does not have the bandwidth of local disks, but it's significantly better than S3. Rightscale again:
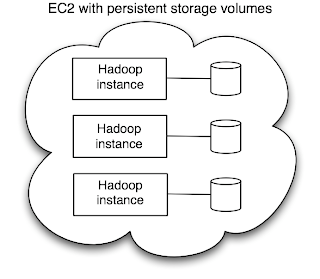 The main departure from the current Hadoop on EC2 approach is the need to maintain a map from storage volume to node type: i.e. we need to remember which volume is a master volume (storing the namenode's data) and which is a worker volume (storing the datanode's data). It would be nice if you could just start up EC2 instances for all the volumes, and have them figure out which is which, but this might not work as the master needs to be started first so its address can be given to the workers in their user data. (This choreography problem could be solved by introducing ZooKeeper, but that's another story.) So for a first cut, we could simply keep two files (locally, or on S3 or even SimpleDB) called master-volumes, and worker-volumes, which simply list the volume IDs for each node type, one per line.
The main departure from the current Hadoop on EC2 approach is the need to maintain a map from storage volume to node type: i.e. we need to remember which volume is a master volume (storing the namenode's data) and which is a worker volume (storing the datanode's data). It would be nice if you could just start up EC2 instances for all the volumes, and have them figure out which is which, but this might not work as the master needs to be started first so its address can be given to the workers in their user data. (This choreography problem could be solved by introducing ZooKeeper, but that's another story.) So for a first cut, we could simply keep two files (locally, or on S3 or even SimpleDB) called master-volumes, and worker-volumes, which simply list the volume IDs for each node type, one per line.
Assume there is one master running the namenode and jobtracker, and n worker nodes each running a datanode and tasktracker.
To create a new cluster
Building this would be a great project to work on - I hope someone does it!
Well, the very next day Amazon launched this service, called Elastic Block Store (EBS). So in this post I thought I'd sketch out how an elastic Hadoop might work.
A bit of background. Currently there are three main ways to use Hadoop with AWS:
1. MapReduce with S3 source and sink
 In this set up, the data resides on S3, and the MapReduce daemons run on a temporary EC2 cluster for the duration of the job run. This works, and is especially convenient if you've already store your data on S3, but you don't get any data locality. Data locality is what enables the magic of MapReduce to work efficiently - the computation is scheduled to run on the machine where the data is stored, so you get huge savings in not having to ship terabytes of data around the network. EC2 does not share nodes with S3 storage, in fact they are often in different data centres, so performance is nowhere near as good as a regular Hadoop cluster where the data in stored in HDFS (see 3. below).
In this set up, the data resides on S3, and the MapReduce daemons run on a temporary EC2 cluster for the duration of the job run. This works, and is especially convenient if you've already store your data on S3, but you don't get any data locality. Data locality is what enables the magic of MapReduce to work efficiently - the computation is scheduled to run on the machine where the data is stored, so you get huge savings in not having to ship terabytes of data around the network. EC2 does not share nodes with S3 storage, in fact they are often in different data centres, so performance is nowhere near as good as a regular Hadoop cluster where the data in stored in HDFS (see 3. below).It's not all doom and gloom, as the bandwidth between EC2 and S3 is actually pretty good, as Rightscale found when they did some measurements.
2. MapReduce from S3 with HDFS staging
 Data is stored on S3 but copied to a temporary HDFS cluster running on EC2. This is just a variation of the previous set-up, which is good if you want to run several jobs against the same input data. You save by only copying the data across the network once, but you pay a little more due to HDFS replication.
Data is stored on S3 but copied to a temporary HDFS cluster running on EC2. This is just a variation of the previous set-up, which is good if you want to run several jobs against the same input data. You save by only copying the data across the network once, but you pay a little more due to HDFS replication.The bottleneck is still copying the data out of S3. (Copying the results back into S3 isn't usually as bad as the output is often an order or two of magnitude smaller than the input.)
3. HDFS on Amazon EC2
 Of course, you could just run a Hadoop cluster on EC2 and store your data there (and not in S3). In this scenario, you are committed to running your EC2 cluster long term, which can prove expensive, although the locality is excellent.
Of course, you could just run a Hadoop cluster on EC2 and store your data there (and not in S3). In this scenario, you are committed to running your EC2 cluster long term, which can prove expensive, although the locality is excellent.These three scenarios demonstrate that you pay for locality. However, there is a gulf between S3 and local disks that EBS fills nicely. EBS does not have the bandwidth of local disks, but it's significantly better than S3. Rightscale again:
The bottom line though is that performance exceeds what we’ve seen for filesystems striped across the four local drives of x-large instances.
Implementing Elastic Hadoop
 The main departure from the current Hadoop on EC2 approach is the need to maintain a map from storage volume to node type: i.e. we need to remember which volume is a master volume (storing the namenode's data) and which is a worker volume (storing the datanode's data). It would be nice if you could just start up EC2 instances for all the volumes, and have them figure out which is which, but this might not work as the master needs to be started first so its address can be given to the workers in their user data. (This choreography problem could be solved by introducing ZooKeeper, but that's another story.) So for a first cut, we could simply keep two files (locally, or on S3 or even SimpleDB) called master-volumes, and worker-volumes, which simply list the volume IDs for each node type, one per line.
The main departure from the current Hadoop on EC2 approach is the need to maintain a map from storage volume to node type: i.e. we need to remember which volume is a master volume (storing the namenode's data) and which is a worker volume (storing the datanode's data). It would be nice if you could just start up EC2 instances for all the volumes, and have them figure out which is which, but this might not work as the master needs to be started first so its address can be given to the workers in their user data. (This choreography problem could be solved by introducing ZooKeeper, but that's another story.) So for a first cut, we could simply keep two files (locally, or on S3 or even SimpleDB) called master-volumes, and worker-volumes, which simply list the volume IDs for each node type, one per line.Assume there is one master running the namenode and jobtracker, and n worker nodes each running a datanode and tasktracker.
To create a new cluster
- Create n + 1 volumes.
- Create the master-volumes file and write the first volume ID into it.
- Create the worker-volumes file and write the remaining volume IDs to it.
- Follow the steps for starting a cluster.
- Start the master instance passing it the master-volumes as user data. On startup the instance attaches to the volume it was told to. It then formats the namenode if it isn't already formatted, then starts the namenode, secondary namenode and jobtracker.
- Start n worker instances passing it the worker-volumes as user data. On startup each instance attaches to the volume on line i, where i is the ami-launch-index of the instance. Each instance then starts a datanode and tasktacker.
- If any worker instances failed to start then launch them again.
- Shutdown the Hadoop cluster daemons.
- Detach the EBS volumes.
- Shutdown the EC2 instances.
- Create m new volumes, where m is the size to grow by.
- Append the m new volume IDs to the worker-volumes file.
- Start m worker instances passing it the worker-volumes as user data. On startup each instance attaches to the volume on line n + i, where i is the ami-launch-index of the instance. Each instance then starts a datanode and tasktacker.
Building this would be a great project to work on - I hope someone does it!
Wednesday, 23 July 2008
Pluggable Hadoop
Update: This quote from Tim O'Reilly in his OSCON keynote today sums up the changes I describe below: "Do less and then create extensibility mechanisms." (via Matt Raible)
I'm noticing an increased desire to make Hadoop more modular. I'm not sure why this is happening now, but it's probably because as more people start using Hadoop it needs to be more malleable (people want to plug in their own implementations of things), and the way to do that in software is through modularity.
Some examples:
I'm noticing an increased desire to make Hadoop more modular. I'm not sure why this is happening now, but it's probably because as more people start using Hadoop it needs to be more malleable (people want to plug in their own implementations of things), and the way to do that in software is through modularity.
Some examples:
Job scheduling
The current scheduler is a simple FIFO scheduler which is adequate for small clusters with a few cooperating users. On larger clusters the best advice has been to use HOD (Hadoop On Demand), but that has its own problems with inefficient cluster utilization. This situation led to a number of proposals to make the scheduler pluggable (HADOOP-2510, HADOOP-3412, HADOOP-3444). Already there is a fair scheduler implementation (like the Completely Fair Scheduler in Linux) from Facebook.HDFS block placement
Today the algorithm for placing a file's blocks across datanodes in the cluster is hardcoded into HDFS, and while it has evolved, it is clear that a one-size-fits-all approach is not necessarily the best approach. Hence the new proposal to support pluggable block placement algorithms.Instrumentation
Finding out what is happening in a distributed system is a hard problem. Today, Hadoop has a metrics API (for gathering statistics from the main components of Hadoop), but there is interest in adding other logging systems, such as X-Trace, via a new instrumentation API.Serialization
The ability to use pluggable serialization frameworks in MapReduce appeared in Hadoop 0.17.0, but has received renewed interest due to the talk around Apache Thrift and Google Protocol Buffers.Component lifecycle
There is work being done to add a lifecyle interface to Hadoop components. One of the goals is to make it easier to subclass components, so they can be customized.Remove dependency cycles
This is really just good engineering practice, but the existence of dependencies makes it harder to understand, modify and extend code. Bill de hÓra did a great analysis of Hadoop's code structure (and its deficiencies), which has lead to some work to enforce module dependencies and remove the cycles.Tuesday, 8 July 2008
RPC and Serialization with Hadoop, Thrift, and Protocol Buffers
Hadoop and related projects like Thrift provide a choice of protocols and formats for doing RPC and serialization. In this post I'll briefly run through them and explain where they came from, how they relate to each other and how Google's newly released Protocol Buffers might fit in.
Protocols are defined using Java interfaces whose arguments and return types are primitives, Strings, Writables, or arrays. These types can all be serialized using Hadoop's specialized serialization format, based on Writable. Combined with the magic of Java dynamic proxies, we get a simple RPC mechanism which for the caller appears to be a Java interface.
The primary benefit of using Writables is in their efficiency. Compared to Java serialization, which would have been an obvious alternative choice, they have a more compact representation. Writables don't store their type in the serialized representation, since at the point of deserialization it is known which type is expected. For the MapReduce code above, the input key is a
From Hadoop 0.17.0 onwards you no longer have to use Writables for key and value types in MapReduce programs. You can use any serialization framework. (Note that this is change is completely independent of Hadoop's RPC mechanism, which still uses Writables - and can only use Writables - as its on-wire format.) So it's easier to use Thrift types, say, throughout your MapReduce program. Or you can even use Java serialization (with some limitations which will be fixed). What's more, you can add your own serialization framework if you like.
Record I/O, Thrift and Protocol Buffers
Another problem with Writables, at least for the MapReduce programmer, is that creating new types is a burden. You have to implement the Writable interface, which means designing the on-wire format, and writing two methods: one to write the data in that format and one to read it back.
Hadoop's Record I/O was created to solve this problem. You write a definition of your types using a record definition language, then run a record compiler to generate Java source code representations of your types. All Record I/O types are Writable, so they plug into Hadoop very easily. As a bonus, you can generate bindings for other languages, so it's easy to read your data files from other programs.
For whatever reason, Record I/O never really took off. It's used in ZooKeeper, but that's about it (and ZooKeeper will move away from it someday). Momentum has switched to Thrift (from Facebook, now in the Apache Incubator), which offers a very similar proposition, but in more languages. Thrift also makes it easy to build a (cross-language) RPC mechanism.
Yesterday, Google open sourced Protocol Buffers, its "language-neutral, platform-neutral, extensible mechanism for serializing structured data". Record I/O, Thrift and Protocol Buffers are really solving the same problem, so it will be interesting to see how this develops. Of course, since we're talking about persistent data formats, nothing's going to go away in the short or medium term while people have significant amounts of data locked up in these formats.
That's why it makes sense to add support in Hadoop for MapReduce using Thrift and Protocol Buffers: so people can process data in the format they have it in. This will be a relatively simple addition.
RPC and Writables
Hadoop has its own RPC mechanism that dates back to when Hadoop was a part of Nutch. It's used throughout Hadoop as the mechanism by which daemons talk to each other. For example, aDataNode communicates with the NameNode using the RPC interface DatanodeProtocol.Protocols are defined using Java interfaces whose arguments and return types are primitives, Strings, Writables, or arrays. These types can all be serialized using Hadoop's specialized serialization format, based on Writable. Combined with the magic of Java dynamic proxies, we get a simple RPC mechanism which for the caller appears to be a Java interface.
MapReduce and Writables
Hadoop uses Writables for another, quite different, purpose: as a serialization format for MapReduce programs. If you've ever written a Hadoop MapReduce program you will have used Writables for the key and value types. For example:
public class MapClass
implements Mapper<LongWritable, Text, Text, IntWritable> {
// ...
}
Text is just a Writable version of Java String.)The primary benefit of using Writables is in their efficiency. Compared to Java serialization, which would have been an obvious alternative choice, they have a more compact representation. Writables don't store their type in the serialized representation, since at the point of deserialization it is known which type is expected. For the MapReduce code above, the input key is a
LongWritable, so an empty LongWritable instance is asked to populate itself from the input data stream.More flexible MapReduce
There are downsides of having to use Writables for MapReduce types, however. For a newcomer to Hadoop it's another hurdle: something else to learn ("why can't I just use a String?"). More seriously, perhaps, is that it's hard to use different binary storage formats for MapReduce input and output. For example, Apache Thrift (see below) is an increasingly popular way of storing binary data. It's possible, but cumbersome and inefficient, to read or write Thrift data from MapReduce.From Hadoop 0.17.0 onwards you no longer have to use Writables for key and value types in MapReduce programs. You can use any serialization framework. (Note that this is change is completely independent of Hadoop's RPC mechanism, which still uses Writables - and can only use Writables - as its on-wire format.) So it's easier to use Thrift types, say, throughout your MapReduce program. Or you can even use Java serialization (with some limitations which will be fixed). What's more, you can add your own serialization framework if you like.
Record I/O, Thrift and Protocol Buffers
Another problem with Writables, at least for the MapReduce programmer, is that creating new types is a burden. You have to implement the Writable interface, which means designing the on-wire format, and writing two methods: one to write the data in that format and one to read it back.Hadoop's Record I/O was created to solve this problem. You write a definition of your types using a record definition language, then run a record compiler to generate Java source code representations of your types. All Record I/O types are Writable, so they plug into Hadoop very easily. As a bonus, you can generate bindings for other languages, so it's easy to read your data files from other programs.
For whatever reason, Record I/O never really took off. It's used in ZooKeeper, but that's about it (and ZooKeeper will move away from it someday). Momentum has switched to Thrift (from Facebook, now in the Apache Incubator), which offers a very similar proposition, but in more languages. Thrift also makes it easy to build a (cross-language) RPC mechanism.
Yesterday, Google open sourced Protocol Buffers, its "language-neutral, platform-neutral, extensible mechanism for serializing structured data". Record I/O, Thrift and Protocol Buffers are really solving the same problem, so it will be interesting to see how this develops. Of course, since we're talking about persistent data formats, nothing's going to go away in the short or medium term while people have significant amounts of data locked up in these formats.
That's why it makes sense to add support in Hadoop for MapReduce using Thrift and Protocol Buffers: so people can process data in the format they have it in. This will be a relatively simple addition.
What Next?
For RPC, where a message is short-lived, changing the mechanism is more viable in the short term. Going back to Hadoop's RPC mechanism, now that both Thrift and Protocol Buffers offer an alternative, it may well be time to evaluate them to see if either can offer a performance boost. It would be a big job to retrofit RPC in Hadoop with another implementation, but if there are significant performance gains to be had, then it would be worth doing.
Subscribe to:
Posts (Atom)