The Cloudera team have just released a website which has a few reports on various Hadoop development metrics. I like the Most Watched Open Jira Issues, as it gives a good summary of what Hadoop Core developers are thinking about.
Personally, I can't wait for the new MapReduce API (HADOOP-1230), which is currently the third most watched issue.
Thursday, 20 November 2008
Thursday, 16 October 2008
Tuesday, 16 September 2008
Hadoop: The Definitive Guide
Update: Fixed feedback link.
The Rough Cut of Hadoop: The Definitive Guide is now up on O'Reilly's site. There are a few chapters available already, at various stages of completion. Remember, it's still pretty rough. I'd love to hear any suggestions for improvements that you may have though. You can submit feedback from Safari where the book is hosted. As the Rough Cuts FAQ explains, I'd like feedback on missing topics, if something is not understandable, and technical mistakes.
Now I just need to go and write the rest of it...
The Rough Cut of Hadoop: The Definitive Guide is now up on O'Reilly's site. There are a few chapters available already, at various stages of completion. Remember, it's still pretty rough. I'd love to hear any suggestions for improvements that you may have though. You can submit feedback from Safari where the book is hosted. As the Rough Cuts FAQ explains, I'd like feedback on missing topics, if something is not understandable, and technical mistakes.
Now I just need to go and write the rest of it...
Thursday, 4 September 2008
Hosting Large Public Datasets on Amazon S3
Update: I just thought of a quick and dirty way of doing this: just store your content on an extra large EC2 instance (holds up to 1690GB) and make the image public. Anyone can access it using their EC2 account, you just get charged for hosting the image.
There's a great deal of interest in large, publicly available datasets (see, for example, this thread from theinfo.org), but for very large datasets it is still expensive to provide the bandwidth to distribute them. Imagine if you could get your hands on the data from a large web crawl, the kind of thing that the Internet Archive produces. I'm sure people would discover some interesting things from it.
Amazon S3 is an obvious choice for storing data for public consumption, but while the cost for storage may be reasonable, the cost for transfer can be crippling since the cost is not under the control of the data provider, being incurred for each transfer (which is initiated by the user).
For example, consider a 1TB dataset. With storage running at $0.15 per GB per month this works out at around $150 per month to host. With transfer costs costing $0.18 per GB, this dataset costs around $180 for each transfer out of Amazon! It's not surprising large datasets are not publicly hosted on S3.
However, transferring data between S3 and EC2 is free, so could we limit transfers from S3 so they are only possible to EC2? You (or anyone else) could run an analysis on EC2 (using Hadoop, say) and only pay for the EC2 time. Or you could transfer it out of EC2 at your own expense. S3 doesn't support this option directly, but it is possible to emulate it with a bit of code.
The idea (suggested by Doug Cutting) is to make objects private on S3 to restrict access generally, then run a proxy on EC2 that is authorized to access the objects. The proxy only accepts connections from within EC2: any client that is outside Amazon's cloud is firewalled out. This combination ensures only EC2 instances can access the S3 objects, thus removing any bandwidth costs.
A few questions:
There's a great deal of interest in large, publicly available datasets (see, for example, this thread from theinfo.org), but for very large datasets it is still expensive to provide the bandwidth to distribute them. Imagine if you could get your hands on the data from a large web crawl, the kind of thing that the Internet Archive produces. I'm sure people would discover some interesting things from it.
Amazon S3 is an obvious choice for storing data for public consumption, but while the cost for storage may be reasonable, the cost for transfer can be crippling since the cost is not under the control of the data provider, being incurred for each transfer (which is initiated by the user).
For example, consider a 1TB dataset. With storage running at $0.15 per GB per month this works out at around $150 per month to host. With transfer costs costing $0.18 per GB, this dataset costs around $180 for each transfer out of Amazon! It's not surprising large datasets are not publicly hosted on S3.
However, transferring data between S3 and EC2 is free, so could we limit transfers from S3 so they are only possible to EC2? You (or anyone else) could run an analysis on EC2 (using Hadoop, say) and only pay for the EC2 time. Or you could transfer it out of EC2 at your own expense. S3 doesn't support this option directly, but it is possible to emulate it with a bit of code.
The idea (suggested by Doug Cutting) is to make objects private on S3 to restrict access generally, then run a proxy on EC2 that is authorized to access the objects. The proxy only accepts connections from within EC2: any client that is outside Amazon's cloud is firewalled out. This combination ensures only EC2 instances can access the S3 objects, thus removing any bandwidth costs.
Implementation
I've written such a proxy. It's a Java servlet that uses the JetS3t library to add the correct Amazon S3Authorization HTTP header to gain access to the owner's objects on S3. If the proxy is running on the EC2 instance with hostname ec2-67-202-43-67.compute-1.amazonaws.com, for example, then a request forhttp://ec2-67-202-43-67.compute-1.amazonaws.com/bucket/objectis proxied to the protected object at
http://s3.amazonaws.com/bucket/objectTo ensure that only clients on EC2 can get access to the proxy I set up an EC2 security group (which limits access to port 80):
ec2-add-group ec2-private-subnet -d "Group for all Amazon EC2 instances."Then by launching the proxy in this group, only machines on EC2 can connect. (Initially, I thought I had to add public IP addresses to the group -- which, incidentally, I found in this forum posting -- but this is not necessary as the public DNS name of an EC2 instance resolves to the private IP address within EC2.) The AWS credentials to gain access to the S3 objects are passed in the user data, along with the hostname of S3:
ec2-authorize ec2-private-subnet -p 80 -s 10.0.0.0/8
ec2-run-instances -k gsg-keypair -g ec2-private-subnet \This AMI (ID
-d "<aws_access_key> <aws_secret_key> s3.amazonaws.com" ami-fffd1996
ami-fffd1996) is publicly available, so anyone can use it by using the commands shown here. (The code is available here, under an Apache 2.0 license, but you don't need this if you only intend to run or use a proxy.)Demo
Here's a resource on S3 that is protected: http://s3.amazonaws.com/tiling/private.txt. When you try to retrieve it you get an authorization error:% curl http://s3.amazonaws.com/tiling/private.txtWith a proxy running, I still can't retrieve the resource via the proxy from outside EC2. It just times out due to the firewall rule:
<?xml version="1.0" encoding="UTF-8"?>
<Error>
<Code>AccessDenied</Code>
<Message>Access Denied</Message>
<RequestId>57E370CDDD9FE044</RequestId>
<HostId>dA+9II1dYAjPE5aNsnRxhVoQ5qy3KCa6frkLg3SyTwzP3i2SQNCU534/v8NXXEnN</HostId>
</Error>
% curl http://ec2-67-202-56-11.compute-1.amazonaws.com/tiling/private.txtBut it does works from an EC2 machine (any EC2 machine):
curl: (7) couldn't connect to host
% curl http://ec2-67-202-56-11.compute-1.amazonaws.com/tiling/private.txt
secret
Conclusion
By running a proxy on EC2, at 10 cents per hour (small instance) - or $72 a month, you can allow folks using EC2 to access your data on S3 for free. While running the proxy is not free, it is a fixed cost that might be acceptable to some organizations, particularly those that have an interest in making data publicly available (but can't stomach large bandwidth costs).A few questions:
- Is this useful?
- Is there a better way of doing it?
- Can we have this built into S3 (please, Amazon)?
Saturday, 23 August 2008
Elastic Hadoop Clusters with Amazon's Elastic Block Store
I gave a talk on Tuesday at the first Hadoop User Group UK about Hadoop and Amazon Web services - how and why you can run Hadoop with AWS. I mentioned how integrating Hadoop with Amazon's "Persistent local storage", which Werner Vogels had pre-announced in April, would be a great feature to have to enable truly elastic Hadoop clusters that you could stop and start on demand.
Well, the very next day Amazon launched this service, called Elastic Block Store (EBS). So in this post I thought I'd sketch out how an elastic Hadoop might work.
A bit of background. Currently there are three main ways to use Hadoop with AWS:
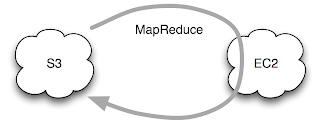 In this set up, the data resides on S3, and the MapReduce daemons run on a temporary EC2 cluster for the duration of the job run. This works, and is especially convenient if you've already store your data on S3, but you don't get any data locality. Data locality is what enables the magic of MapReduce to work efficiently - the computation is scheduled to run on the machine where the data is stored, so you get huge savings in not having to ship terabytes of data around the network. EC2 does not share nodes with S3 storage, in fact they are often in different data centres, so performance is nowhere near as good as a regular Hadoop cluster where the data in stored in HDFS (see 3. below).
In this set up, the data resides on S3, and the MapReduce daemons run on a temporary EC2 cluster for the duration of the job run. This works, and is especially convenient if you've already store your data on S3, but you don't get any data locality. Data locality is what enables the magic of MapReduce to work efficiently - the computation is scheduled to run on the machine where the data is stored, so you get huge savings in not having to ship terabytes of data around the network. EC2 does not share nodes with S3 storage, in fact they are often in different data centres, so performance is nowhere near as good as a regular Hadoop cluster where the data in stored in HDFS (see 3. below).
It's not all doom and gloom, as the bandwidth between EC2 and S3 is actually pretty good, as Rightscale found when they did some measurements.
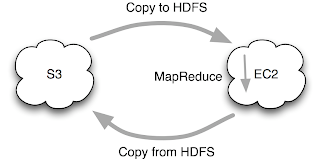 Data is stored on S3 but copied to a temporary HDFS cluster running on EC2. This is just a variation of the previous set-up, which is good if you want to run several jobs against the same input data. You save by only copying the data across the network once, but you pay a little more due to HDFS replication.
Data is stored on S3 but copied to a temporary HDFS cluster running on EC2. This is just a variation of the previous set-up, which is good if you want to run several jobs against the same input data. You save by only copying the data across the network once, but you pay a little more due to HDFS replication.
The bottleneck is still copying the data out of S3. (Copying the results back into S3 isn't usually as bad as the output is often an order or two of magnitude smaller than the input.)
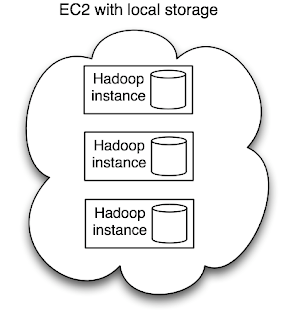 Of course, you could just run a Hadoop cluster on EC2 and store your data there (and not in S3). In this scenario, you are committed to running your EC2 cluster long term, which can prove expensive, although the locality is excellent.
Of course, you could just run a Hadoop cluster on EC2 and store your data there (and not in S3). In this scenario, you are committed to running your EC2 cluster long term, which can prove expensive, although the locality is excellent.
These three scenarios demonstrate that you pay for locality. However, there is a gulf between S3 and local disks that EBS fills nicely. EBS does not have the bandwidth of local disks, but it's significantly better than S3. Rightscale again:
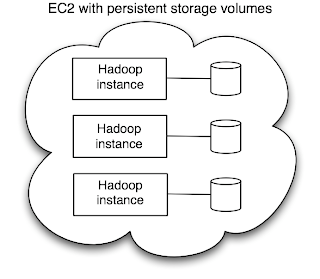 The main departure from the current Hadoop on EC2 approach is the need to maintain a map from storage volume to node type: i.e. we need to remember which volume is a master volume (storing the namenode's data) and which is a worker volume (storing the datanode's data). It would be nice if you could just start up EC2 instances for all the volumes, and have them figure out which is which, but this might not work as the master needs to be started first so its address can be given to the workers in their user data. (This choreography problem could be solved by introducing ZooKeeper, but that's another story.) So for a first cut, we could simply keep two files (locally, or on S3 or even SimpleDB) called master-volumes, and worker-volumes, which simply list the volume IDs for each node type, one per line.
The main departure from the current Hadoop on EC2 approach is the need to maintain a map from storage volume to node type: i.e. we need to remember which volume is a master volume (storing the namenode's data) and which is a worker volume (storing the datanode's data). It would be nice if you could just start up EC2 instances for all the volumes, and have them figure out which is which, but this might not work as the master needs to be started first so its address can be given to the workers in their user data. (This choreography problem could be solved by introducing ZooKeeper, but that's another story.) So for a first cut, we could simply keep two files (locally, or on S3 or even SimpleDB) called master-volumes, and worker-volumes, which simply list the volume IDs for each node type, one per line.
Assume there is one master running the namenode and jobtracker, and n worker nodes each running a datanode and tasktracker.
To create a new cluster
Building this would be a great project to work on - I hope someone does it!
Well, the very next day Amazon launched this service, called Elastic Block Store (EBS). So in this post I thought I'd sketch out how an elastic Hadoop might work.
A bit of background. Currently there are three main ways to use Hadoop with AWS:
1. MapReduce with S3 source and sink
 In this set up, the data resides on S3, and the MapReduce daemons run on a temporary EC2 cluster for the duration of the job run. This works, and is especially convenient if you've already store your data on S3, but you don't get any data locality. Data locality is what enables the magic of MapReduce to work efficiently - the computation is scheduled to run on the machine where the data is stored, so you get huge savings in not having to ship terabytes of data around the network. EC2 does not share nodes with S3 storage, in fact they are often in different data centres, so performance is nowhere near as good as a regular Hadoop cluster where the data in stored in HDFS (see 3. below).
In this set up, the data resides on S3, and the MapReduce daemons run on a temporary EC2 cluster for the duration of the job run. This works, and is especially convenient if you've already store your data on S3, but you don't get any data locality. Data locality is what enables the magic of MapReduce to work efficiently - the computation is scheduled to run on the machine where the data is stored, so you get huge savings in not having to ship terabytes of data around the network. EC2 does not share nodes with S3 storage, in fact they are often in different data centres, so performance is nowhere near as good as a regular Hadoop cluster where the data in stored in HDFS (see 3. below).It's not all doom and gloom, as the bandwidth between EC2 and S3 is actually pretty good, as Rightscale found when they did some measurements.
2. MapReduce from S3 with HDFS staging
 Data is stored on S3 but copied to a temporary HDFS cluster running on EC2. This is just a variation of the previous set-up, which is good if you want to run several jobs against the same input data. You save by only copying the data across the network once, but you pay a little more due to HDFS replication.
Data is stored on S3 but copied to a temporary HDFS cluster running on EC2. This is just a variation of the previous set-up, which is good if you want to run several jobs against the same input data. You save by only copying the data across the network once, but you pay a little more due to HDFS replication.The bottleneck is still copying the data out of S3. (Copying the results back into S3 isn't usually as bad as the output is often an order or two of magnitude smaller than the input.)
3. HDFS on Amazon EC2
 Of course, you could just run a Hadoop cluster on EC2 and store your data there (and not in S3). In this scenario, you are committed to running your EC2 cluster long term, which can prove expensive, although the locality is excellent.
Of course, you could just run a Hadoop cluster on EC2 and store your data there (and not in S3). In this scenario, you are committed to running your EC2 cluster long term, which can prove expensive, although the locality is excellent.These three scenarios demonstrate that you pay for locality. However, there is a gulf between S3 and local disks that EBS fills nicely. EBS does not have the bandwidth of local disks, but it's significantly better than S3. Rightscale again:
The bottom line though is that performance exceeds what we’ve seen for filesystems striped across the four local drives of x-large instances.
Implementing Elastic Hadoop
 The main departure from the current Hadoop on EC2 approach is the need to maintain a map from storage volume to node type: i.e. we need to remember which volume is a master volume (storing the namenode's data) and which is a worker volume (storing the datanode's data). It would be nice if you could just start up EC2 instances for all the volumes, and have them figure out which is which, but this might not work as the master needs to be started first so its address can be given to the workers in their user data. (This choreography problem could be solved by introducing ZooKeeper, but that's another story.) So for a first cut, we could simply keep two files (locally, or on S3 or even SimpleDB) called master-volumes, and worker-volumes, which simply list the volume IDs for each node type, one per line.
The main departure from the current Hadoop on EC2 approach is the need to maintain a map from storage volume to node type: i.e. we need to remember which volume is a master volume (storing the namenode's data) and which is a worker volume (storing the datanode's data). It would be nice if you could just start up EC2 instances for all the volumes, and have them figure out which is which, but this might not work as the master needs to be started first so its address can be given to the workers in their user data. (This choreography problem could be solved by introducing ZooKeeper, but that's another story.) So for a first cut, we could simply keep two files (locally, or on S3 or even SimpleDB) called master-volumes, and worker-volumes, which simply list the volume IDs for each node type, one per line.Assume there is one master running the namenode and jobtracker, and n worker nodes each running a datanode and tasktracker.
To create a new cluster
- Create n + 1 volumes.
- Create the master-volumes file and write the first volume ID into it.
- Create the worker-volumes file and write the remaining volume IDs to it.
- Follow the steps for starting a cluster.
- Start the master instance passing it the master-volumes as user data. On startup the instance attaches to the volume it was told to. It then formats the namenode if it isn't already formatted, then starts the namenode, secondary namenode and jobtracker.
- Start n worker instances passing it the worker-volumes as user data. On startup each instance attaches to the volume on line i, where i is the ami-launch-index of the instance. Each instance then starts a datanode and tasktacker.
- If any worker instances failed to start then launch them again.
- Shutdown the Hadoop cluster daemons.
- Detach the EBS volumes.
- Shutdown the EC2 instances.
- Create m new volumes, where m is the size to grow by.
- Append the m new volume IDs to the worker-volumes file.
- Start m worker instances passing it the worker-volumes as user data. On startup each instance attaches to the volume on line n + i, where i is the ami-launch-index of the instance. Each instance then starts a datanode and tasktacker.
Building this would be a great project to work on - I hope someone does it!
Wednesday, 23 July 2008
Pluggable Hadoop
Update: This quote from Tim O'Reilly in his OSCON keynote today sums up the changes I describe below: "Do less and then create extensibility mechanisms." (via Matt Raible)
I'm noticing an increased desire to make Hadoop more modular. I'm not sure why this is happening now, but it's probably because as more people start using Hadoop it needs to be more malleable (people want to plug in their own implementations of things), and the way to do that in software is through modularity.
Some examples:
I'm noticing an increased desire to make Hadoop more modular. I'm not sure why this is happening now, but it's probably because as more people start using Hadoop it needs to be more malleable (people want to plug in their own implementations of things), and the way to do that in software is through modularity.
Some examples:
Job scheduling
The current scheduler is a simple FIFO scheduler which is adequate for small clusters with a few cooperating users. On larger clusters the best advice has been to use HOD (Hadoop On Demand), but that has its own problems with inefficient cluster utilization. This situation led to a number of proposals to make the scheduler pluggable (HADOOP-2510, HADOOP-3412, HADOOP-3444). Already there is a fair scheduler implementation (like the Completely Fair Scheduler in Linux) from Facebook.HDFS block placement
Today the algorithm for placing a file's blocks across datanodes in the cluster is hardcoded into HDFS, and while it has evolved, it is clear that a one-size-fits-all approach is not necessarily the best approach. Hence the new proposal to support pluggable block placement algorithms.Instrumentation
Finding out what is happening in a distributed system is a hard problem. Today, Hadoop has a metrics API (for gathering statistics from the main components of Hadoop), but there is interest in adding other logging systems, such as X-Trace, via a new instrumentation API.Serialization
The ability to use pluggable serialization frameworks in MapReduce appeared in Hadoop 0.17.0, but has received renewed interest due to the talk around Apache Thrift and Google Protocol Buffers.Component lifecycle
There is work being done to add a lifecyle interface to Hadoop components. One of the goals is to make it easier to subclass components, so they can be customized.Remove dependency cycles
This is really just good engineering practice, but the existence of dependencies makes it harder to understand, modify and extend code. Bill de hÓra did a great analysis of Hadoop's code structure (and its deficiencies), which has lead to some work to enforce module dependencies and remove the cycles.Tuesday, 8 July 2008
RPC and Serialization with Hadoop, Thrift, and Protocol Buffers
Hadoop and related projects like Thrift provide a choice of protocols and formats for doing RPC and serialization. In this post I'll briefly run through them and explain where they came from, how they relate to each other and how Google's newly released Protocol Buffers might fit in.
Protocols are defined using Java interfaces whose arguments and return types are primitives, Strings, Writables, or arrays. These types can all be serialized using Hadoop's specialized serialization format, based on Writable. Combined with the magic of Java dynamic proxies, we get a simple RPC mechanism which for the caller appears to be a Java interface.
The primary benefit of using Writables is in their efficiency. Compared to Java serialization, which would have been an obvious alternative choice, they have a more compact representation. Writables don't store their type in the serialized representation, since at the point of deserialization it is known which type is expected. For the MapReduce code above, the input key is a
From Hadoop 0.17.0 onwards you no longer have to use Writables for key and value types in MapReduce programs. You can use any serialization framework. (Note that this is change is completely independent of Hadoop's RPC mechanism, which still uses Writables - and can only use Writables - as its on-wire format.) So it's easier to use Thrift types, say, throughout your MapReduce program. Or you can even use Java serialization (with some limitations which will be fixed). What's more, you can add your own serialization framework if you like.
Record I/O, Thrift and Protocol Buffers
Another problem with Writables, at least for the MapReduce programmer, is that creating new types is a burden. You have to implement the Writable interface, which means designing the on-wire format, and writing two methods: one to write the data in that format and one to read it back.
Hadoop's Record I/O was created to solve this problem. You write a definition of your types using a record definition language, then run a record compiler to generate Java source code representations of your types. All Record I/O types are Writable, so they plug into Hadoop very easily. As a bonus, you can generate bindings for other languages, so it's easy to read your data files from other programs.
For whatever reason, Record I/O never really took off. It's used in ZooKeeper, but that's about it (and ZooKeeper will move away from it someday). Momentum has switched to Thrift (from Facebook, now in the Apache Incubator), which offers a very similar proposition, but in more languages. Thrift also makes it easy to build a (cross-language) RPC mechanism.
Yesterday, Google open sourced Protocol Buffers, its "language-neutral, platform-neutral, extensible mechanism for serializing structured data". Record I/O, Thrift and Protocol Buffers are really solving the same problem, so it will be interesting to see how this develops. Of course, since we're talking about persistent data formats, nothing's going to go away in the short or medium term while people have significant amounts of data locked up in these formats.
That's why it makes sense to add support in Hadoop for MapReduce using Thrift and Protocol Buffers: so people can process data in the format they have it in. This will be a relatively simple addition.
RPC and Writables
Hadoop has its own RPC mechanism that dates back to when Hadoop was a part of Nutch. It's used throughout Hadoop as the mechanism by which daemons talk to each other. For example, aDataNode communicates with the NameNode using the RPC interface DatanodeProtocol.Protocols are defined using Java interfaces whose arguments and return types are primitives, Strings, Writables, or arrays. These types can all be serialized using Hadoop's specialized serialization format, based on Writable. Combined with the magic of Java dynamic proxies, we get a simple RPC mechanism which for the caller appears to be a Java interface.
MapReduce and Writables
Hadoop uses Writables for another, quite different, purpose: as a serialization format for MapReduce programs. If you've ever written a Hadoop MapReduce program you will have used Writables for the key and value types. For example:
public class MapClass
implements Mapper<LongWritable, Text, Text, IntWritable> {
// ...
}
Text is just a Writable version of Java String.)The primary benefit of using Writables is in their efficiency. Compared to Java serialization, which would have been an obvious alternative choice, they have a more compact representation. Writables don't store their type in the serialized representation, since at the point of deserialization it is known which type is expected. For the MapReduce code above, the input key is a
LongWritable, so an empty LongWritable instance is asked to populate itself from the input data stream.More flexible MapReduce
There are downsides of having to use Writables for MapReduce types, however. For a newcomer to Hadoop it's another hurdle: something else to learn ("why can't I just use a String?"). More seriously, perhaps, is that it's hard to use different binary storage formats for MapReduce input and output. For example, Apache Thrift (see below) is an increasingly popular way of storing binary data. It's possible, but cumbersome and inefficient, to read or write Thrift data from MapReduce.From Hadoop 0.17.0 onwards you no longer have to use Writables for key and value types in MapReduce programs. You can use any serialization framework. (Note that this is change is completely independent of Hadoop's RPC mechanism, which still uses Writables - and can only use Writables - as its on-wire format.) So it's easier to use Thrift types, say, throughout your MapReduce program. Or you can even use Java serialization (with some limitations which will be fixed). What's more, you can add your own serialization framework if you like.
Record I/O, Thrift and Protocol Buffers
Another problem with Writables, at least for the MapReduce programmer, is that creating new types is a burden. You have to implement the Writable interface, which means designing the on-wire format, and writing two methods: one to write the data in that format and one to read it back.Hadoop's Record I/O was created to solve this problem. You write a definition of your types using a record definition language, then run a record compiler to generate Java source code representations of your types. All Record I/O types are Writable, so they plug into Hadoop very easily. As a bonus, you can generate bindings for other languages, so it's easy to read your data files from other programs.
For whatever reason, Record I/O never really took off. It's used in ZooKeeper, but that's about it (and ZooKeeper will move away from it someday). Momentum has switched to Thrift (from Facebook, now in the Apache Incubator), which offers a very similar proposition, but in more languages. Thrift also makes it easy to build a (cross-language) RPC mechanism.
Yesterday, Google open sourced Protocol Buffers, its "language-neutral, platform-neutral, extensible mechanism for serializing structured data". Record I/O, Thrift and Protocol Buffers are really solving the same problem, so it will be interesting to see how this develops. Of course, since we're talking about persistent data formats, nothing's going to go away in the short or medium term while people have significant amounts of data locked up in these formats.
That's why it makes sense to add support in Hadoop for MapReduce using Thrift and Protocol Buffers: so people can process data in the format they have it in. This will be a relatively simple addition.
What Next?
For RPC, where a message is short-lived, changing the mechanism is more viable in the short term. Going back to Hadoop's RPC mechanism, now that both Thrift and Protocol Buffers offer an alternative, it may well be time to evaluate them to see if either can offer a performance boost. It would be a big job to retrofit RPC in Hadoop with another implementation, but if there are significant performance gains to be had, then it would be worth doing.Thursday, 3 July 2008
Hadoop beats terabyte sort record
Hadoop has beaten the record for the terabyte sort benchmark, bringing it from 297 seconds to 209. Owen O'Malley wrote the MapReduce program (which by the way has a clever partitioner to ensure the reducer outputs are globally sorted and not just sorted per output partition, which is what the default sort does), and then ran it on 910 nodes on Yahoo!'s cluster. There are more details in Owen's blog post (and there's a link to the benchmark page which has a PDF explaining his program). You can also look at the code in trunk.
Well done Owen and well done Hadoop!
Well done Owen and well done Hadoop!
Friday, 20 June 2008
Hadoop Query Languages
If you want a high-level query language for drilling into your huge Hadoop dataset, then you've got some choice:
Meanwhile, to learn more I recommend Pig Latin: A Not-So-Foreign Language for Data Processing (by Chris Olston et al), and the slides and videos from the Hadoop Summit.
(And I haven't even included Cascading, from Chris K. Wensel, which, while not a query language per se, is an abstraction built on MapReduce for building data processing flows in Java or Groovy using a plumbing metaphor with constructs such as taps, pipes, and flows. Well worth a look too.)
- Pig, from Yahoo! and now incubating at Apache, has an imperative language called Pig Latin for performing operations on large data files.
- Jaql, from IBM and soon to be open sourced, is a declarative query language for JSON data.
- Hive, from Facebook and soon to become a Hadoop contrib module, is a data warehouse system with a declarative query language that is a hybrid of SQL and Hadoop streaming.
Meanwhile, to learn more I recommend Pig Latin: A Not-So-Foreign Language for Data Processing (by Chris Olston et al), and the slides and videos from the Hadoop Summit.
(And I haven't even included Cascading, from Chris K. Wensel, which, while not a query language per se, is an abstraction built on MapReduce for building data processing flows in Java or Groovy using a plumbing metaphor with constructs such as taps, pipes, and flows. Well worth a look too.)
Friday, 13 June 2008
"The Next Big Thing"
James Hamilton on The Next Big Thing:
I think we're only beginning to see interesting data processing being done in the cloud - there's much more to come.
Storing blobs in the sky is fine but pretty reproducible by any competitor. Storing structured data as well as blobs is considerably more interesting but what has even more lasting business value is the storing data in the cloud AND providing a programming platform for multi-thousand node data analysis. Almost every reasonable business on the planet has a complex set of dimensions that need to be optimized.
I think we're only beginning to see interesting data processing being done in the cloud - there's much more to come.
Friday, 30 May 2008
Bluetooth Castle
 Today I visited Raglan Castle in Monmouthshire with my family. Cadw, the government body that manages the castle, were running a trial to deliver audio files to visitors' mobile phones using Bluetooth. As I walked through the entrance I simply made my phone discoverable, waited a few seconds for the MP3 to download, then started listening to a guided tour of the castle. It's a great use of the technology: it just worked.
Today I visited Raglan Castle in Monmouthshire with my family. Cadw, the government body that manages the castle, were running a trial to deliver audio files to visitors' mobile phones using Bluetooth. As I walked through the entrance I simply made my phone discoverable, waited a few seconds for the MP3 to download, then started listening to a guided tour of the castle. It's a great use of the technology: it just worked.The talk only lasted a few minutes, so we had plenty of time afterwards to run around the ruins.
A couple of technical questions that sprang to mind:
- How would you set up a server to push files over Bluetooth? (There are loads of ways you could use this - maps of the local area at transport hubs, sharing the schedule at conferences, random photo of the day at home, etc.)
- Can you make audio files navigable? That is, make it easy to go to the part of audio file that is about a given exhibit by typing in the exhibit's number? (This problem reminds me of Cliff Schmidt's talk about the Talking Book Device at ApacheCon EU 2008.)
Tuesday, 22 April 2008
Portable Cloud Computing
Last July I asked "Why are there no Amazon S3/EC2 competitors?", lamenting the lack of competition in the utility or cloud computing market and the implications for disaster recovery. Closely tied to disaster recover is portability -- the ability to switch between different utility computing providers as easily as I switch electricity suppliers. (OK, that can be a pain, at least in the UK, but it doesn't require rewiring my house.)
It's useful to compare Amazon Web Services with Google's recently launched App Engine in these terms. In some sense they compete, but they are strikingly different offerings. Amazon's services are bottom up: "here's a CPU, now install your own software". Google's is top down: "write some code to these APIs and we'll scale it for you". There's no way I can take my EC2 services and run them on App Engine. But I can do the reverse -- sort of -- thanks to AppDrop.
And that's the thing. What I would love is a utility service from different providers that I can switch between. That's one of the meanings of "utility", after all. (Moving lots of data between providers may make this difficult or expensive to do in practice -- "data inertia" -- but that's not a reason not to have the capability.)
There are at least two ways this can happen. One's the AppDrop approach -- emulate Google's API and provide an alternative place to run applications, in this case it's EC2.
However, there's another way: build "standard, non-proprietary cloud APIs with open-source implementations", as Doug Cutting says on his blog post Cloud: commodity or proprietary? In this world, applications use a common API, and host with whichever provider they fancy. Bottom up offerings like Amazon's facilitate this approach: the underlying platforms may differ, but it's easy to run your application on the provided platform -- for example, by building an Amazon AMI. Google's top down approach is not so amenable, application developers are locked-in to the APIs Google provide. (Of course, Google may open this platform up more over time, but it remains to be seen if they will open it up to the extent of being able to run arbitrary executables.)
As Doug notes, Hadoop is providing a lot of the building blocks for building cloud services: filesystem (HDFS), database (HBase), computation (MapReduce), coordination (ZooKeeper). And here, perhaps, is where the two approaches may meet -- AppDrop could be backed by HBase (or indeed Hypertable), or HBase (and Hypertable) could have an open API which your application could use directly.
Rails or Django on HBase, anyone?
It's useful to compare Amazon Web Services with Google's recently launched App Engine in these terms. In some sense they compete, but they are strikingly different offerings. Amazon's services are bottom up: "here's a CPU, now install your own software". Google's is top down: "write some code to these APIs and we'll scale it for you". There's no way I can take my EC2 services and run them on App Engine. But I can do the reverse -- sort of -- thanks to AppDrop.
And that's the thing. What I would love is a utility service from different providers that I can switch between. That's one of the meanings of "utility", after all. (Moving lots of data between providers may make this difficult or expensive to do in practice -- "data inertia" -- but that's not a reason not to have the capability.)
There are at least two ways this can happen. One's the AppDrop approach -- emulate Google's API and provide an alternative place to run applications, in this case it's EC2.
However, there's another way: build "standard, non-proprietary cloud APIs with open-source implementations", as Doug Cutting says on his blog post Cloud: commodity or proprietary? In this world, applications use a common API, and host with whichever provider they fancy. Bottom up offerings like Amazon's facilitate this approach: the underlying platforms may differ, but it's easy to run your application on the provided platform -- for example, by building an Amazon AMI. Google's top down approach is not so amenable, application developers are locked-in to the APIs Google provide. (Of course, Google may open this platform up more over time, but it remains to be seen if they will open it up to the extent of being able to run arbitrary executables.)
As Doug notes, Hadoop is providing a lot of the building blocks for building cloud services: filesystem (HDFS), database (HBase), computation (MapReduce), coordination (ZooKeeper). And here, perhaps, is where the two approaches may meet -- AppDrop could be backed by HBase (or indeed Hypertable), or HBase (and Hypertable) could have an open API which your application could use directly.
Rails or Django on HBase, anyone?
Monday, 14 April 2008
Hadoop at ApacheCon Europe
On Friday in Amsterdam there was a lot of Hadoop on the menu at ApacheCon. I kicked it off at 9am with A Tour of Apache Hadoop, Owen O'Malley followed with Programming with Hadoop’s Map/Reduce, and Allen Wittenauer finished off after lunch with Deploying Grid Services using Apache Hadoop. Find the slides on the Hadoop Presentations page of the wiki. I've also embedded mine below.
I only saw half of Allen's talk as I had to catch my plane, but I was there long enough to see his interesting choice of HDFS users... :)
Also at ApacheCon I enjoyed meeting the Mahout people (Grant, Karl, Isabel and Erik), seeing Cliff Schmidt's keynote, and generally meeting interesting people.
I only saw half of Allen's talk as I had to catch my plane, but I was there long enough to see his interesting choice of HDFS users... :)
Also at ApacheCon I enjoyed meeting the Mahout people (Grant, Karl, Isabel and Erik), seeing Cliff Schmidt's keynote, and generally meeting interesting people.
Sunday, 30 March 2008
Turn off the lights when you're not using them, please
One of the things that struck me about this week's new Amazon EC2 features was the pricing model for Elastic IP addresses:
I think one way of viewing EC2 - and the other Amazon utility services - is as a way of putting very fine-grained costs on various computing operations. So will such a pricing model drive us to minimise the computing resources we use to solve a particular problem? My hope is that making computing costs more transparent will at least make us think about what we're using more, in the way metered electricity makes (some of) us think twice about leaving the lights on. Perhaps we'll even start talking about optimizing for monetary cost or energy usage rather than purely raw speed?
$0.01 per hour when not mapped to a running instanceThe idea is to encourage people to stop hogging public IP addresses, which are a limited resource, when they don't need them.
I think one way of viewing EC2 - and the other Amazon utility services - is as a way of putting very fine-grained costs on various computing operations. So will such a pricing model drive us to minimise the computing resources we use to solve a particular problem? My hope is that making computing costs more transparent will at least make us think about what we're using more, in the way metered electricity makes (some of) us think twice about leaving the lights on. Perhaps we'll even start talking about optimizing for monetary cost or energy usage rather than purely raw speed?
Sunday, 23 March 2008
Visualizing Easter
I made this image a few years ago (as a postcard to give to friends), but it's appropriate to show again today as it's a neat visual demonstration that Easter this year is the earliest this century.
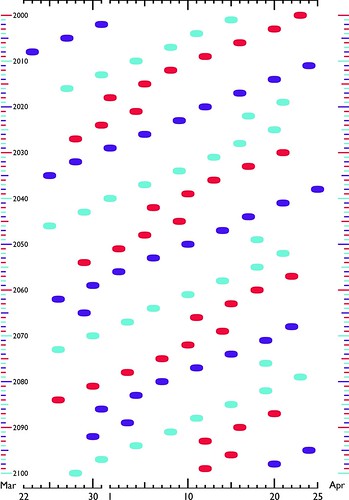
The scale at the bottom shows the maximum range of Easter: from 22 March to 25 April. You can read more about the image here.
The image is licensed under a Creative Commons Attribution-Noncommercial-Share Alike license, so you are free to share and remix it for non-commercial purposes.
The scale at the bottom shows the maximum range of Easter: from 22 March to 25 April. You can read more about the image here.
The image is licensed under a Creative Commons Attribution-Noncommercial-Share Alike license, so you are free to share and remix it for non-commercial purposes.
Saturday, 22 March 2008
Learning MapReduce
Update: I've posted my answers to the exercises. Let me know if you find any mistakes. Also: Tamara Petroff has posted a write up of the session.
On Wednesday [19 March], I ran a session at SPA 2008 entitled "Understanding MapReduce with Hadoop". SPA is a very hands-on conference, with many sessions having a methodological slant, so I wanted to get people who had never encountered MapReduce before actually writing MapReduce programs. I only had 75 minutes, so I decided against getting people coding on their laptops. (In hindsight this was a good decision, as I went to several other sessions where we struggled to get the software installed.) Instead, we wrote MapReduce programs on paper, using a simplified notation.
It seemed to work. For the first half hour, I gave as minimal an introduction to MapReduce as I could, then the whole group spent the next half hour working in pairs to express the solutions to a number of exercises as MapReduce programs. We spent the last 15 minutes comparing notes and discussing some of the solutions to the problems.
There were six exercises, presented in rough order of difficulty, and I'm pleased to say that every pair managed to solve at least one. Here's some of the feedback I got:
Finally, thanks to Robert Chatley for being a guinea pig for the exercises, and for helping out on the day with participants' questions during the session.
On Wednesday [19 March], I ran a session at SPA 2008 entitled "Understanding MapReduce with Hadoop". SPA is a very hands-on conference, with many sessions having a methodological slant, so I wanted to get people who had never encountered MapReduce before actually writing MapReduce programs. I only had 75 minutes, so I decided against getting people coding on their laptops. (In hindsight this was a good decision, as I went to several other sessions where we struggled to get the software installed.) Instead, we wrote MapReduce programs on paper, using a simplified notation.
It seemed to work. For the first half hour, I gave as minimal an introduction to MapReduce as I could, then the whole group spent the next half hour working in pairs to express the solutions to a number of exercises as MapReduce programs. We spent the last 15 minutes comparing notes and discussing some of the solutions to the problems.
There were six exercises, presented in rough order of difficulty, and I'm pleased to say that every pair managed to solve at least one. Here's some of the feedback I got:
- Some struggled to know what input data formats to use. Perhaps I glossed over this too much - I didn't want people to worry about precisely how the data was encoded - but I could have emphasised more that you can have the data presented to your map function in any way that's convenient.
- While most people understood the notation I used for writing the map and reduce functions, it did cause some confusion. For example, someone wanted to see the example code again so they could understand what was going on. And another person said it took a while to realise that they could do arbitrary processing as a part of the map and reduce functions. It would be interesting to do the session again but using Java notation.
- It was quite common for people to try to do complex things in their map and reduce functions - they felt bad if they just used an identity function, because it was somehow a waste. And on a related note, chaining map reduce jobs together wasn't obvious to many. But once pointed out, folks had an "aha!" moment and were quick to exploit it.
- The fact that you typically get multiple reduce outputs prompted questions from some - "but how do you combine them into a single answer?". Talking about chained MapReduce helped here again.
- Everyone agreed that it wasn't much like functional programming.
- Find the [number of] hits by 5 minute timeslot for a website given its access logs.
- Find the pages with over 1 million hits in day for a website given its access logs.
- Find the pages that link to each page in a collection of webpages.
- Calculate the proportion of lines that match a given regular expression for a collection of documents.
- Sort tabular data by a primary and secondary column.
- Find the most popular pages for a website given its access logs.
Finally, thanks to Robert Chatley for being a guinea pig for the exercises, and for helping out on the day with participants' questions during the session.
Tuesday, 18 March 2008
"Disks have become tapes"
MapReduce is a programming model for processing vast amounts of data. One of the reasons that it works so well is because it exploits a sweet spot of modern disk drive technology trends. In essence MapReduce works by repeatedly sorting and merging data that is streamed to and from disk at the transfer rate of the disk. Contrast this to accessing data from a relational database that operates at the seek rate of the disk (seeking is the process of moving the disk's head to a particular place on the disk to read or write data).
So why is this interesting? Well, look at the trends in seek time and transfer rate. Seek time has grown at about 5% a year, whereas transfer rate at about 20% [1]. Seek time is growing more slowly than transfer rate - so it pays to use a model that operates at the transfer rate. Which is what MapReduce does. I first saw this observation in Doug Cutting's talk, with Eric Baldeschwieler, at OSCON last year, where he worked through the numbers for updating a 1 terabyte database using the two paradigms B-Tree (seek-limited) and Sort/Merge (transfer-limited). (See the slides and video for more detail.)
The general point was well summed up by Jim Gray in an interview in ACM Queue from 2003:
But even the growth of transfer rate is dwarfed by another measure of disk drives - capacity, which is growing at about 50% a year. David DeWitt argues that since the effective transfer rate of drives is falling we need database systems that work with this trend - such as column-store databases and wider use of compression (since this effectively increases the transfer rate of a disk). Of existing databases he says:
[1] See Trends in Disk Technology by Michael D. Dahlin for changes between 1987-1994. For the period since then these figures still hold - as it's relatively easy to check using manufacturer's data sheets, although with seek time it's harder to tell since the definitions seem to change from year to year and from manufacturer to manufacturer. Still, 5% is generous.
So why is this interesting? Well, look at the trends in seek time and transfer rate. Seek time has grown at about 5% a year, whereas transfer rate at about 20% [1]. Seek time is growing more slowly than transfer rate - so it pays to use a model that operates at the transfer rate. Which is what MapReduce does. I first saw this observation in Doug Cutting's talk, with Eric Baldeschwieler, at OSCON last year, where he worked through the numbers for updating a 1 terabyte database using the two paradigms B-Tree (seek-limited) and Sort/Merge (transfer-limited). (See the slides and video for more detail.)
The general point was well summed up by Jim Gray in an interview in ACM Queue from 2003:
... programmers have to start thinking of the disk as a sequential device rather than a random access device.Or the more pithy: "Disks have become tapes." (Quoted by David DeWitt.)
But even the growth of transfer rate is dwarfed by another measure of disk drives - capacity, which is growing at about 50% a year. David DeWitt argues that since the effective transfer rate of drives is falling we need database systems that work with this trend - such as column-store databases and wider use of compression (since this effectively increases the transfer rate of a disk). Of existing databases he says:
Already we see transaction processing systems running on farms of mostly empty disk drives to obtain enough seeks/second to satisfy their transaction processing rates.But this applies to transfer rate too (or if it doesn't yet, it will). Replace "seeks" with "transfers" and "transaction processing" with "MapReduce" and I think over time we'll start seeing Hadoop installations that choose to use large numbers of smaller capacity disks to maximize their processing rates.
[1] See Trends in Disk Technology by Michael D. Dahlin for changes between 1987-1994. For the period since then these figures still hold - as it's relatively easy to check using manufacturer's data sheets, although with seek time it's harder to tell since the definitions seem to change from year to year and from manufacturer to manufacturer. Still, 5% is generous.
Sunday, 2 March 2008
MapReduce without the Reduce
There's a class of MapReduce applications that use Hadoop just for its distributed processing capabilities. Telltale signs are:
1. Little or no input data of note. (Certainly not large files stored in HDFS.)
2. Map tasks are therefore not limited by their ability to consume input, but by their ability to run the task, which depending on the application may be CPU-bound or IO-bound.
3. Little or map output.
4. No reducers (set by
This seems to work well - indeed the CopyFiles program in Hadoop (aka
1. The input to each map task is a source file and a destination.
2. The map task is limited by its ability to copy the source to the destination (IO-bound).
3. The map output is used as a convenience to record files that were skipped.
4. There are no reducers.
Combined with Streaming this is a neat way to distribute your processing in any language. You do need a Hadoop cluster, it is true, but CPU-intensive jobs would happily co-exist with more traditional MapReduce jobs, which are typically fairly light on CPU usage.
1. Little or no input data of note. (Certainly not large files stored in HDFS.)
2. Map tasks are therefore not limited by their ability to consume input, but by their ability to run the task, which depending on the application may be CPU-bound or IO-bound.
3. Little or map output.
4. No reducers (set by
conf.setNumReduceTasks(0)).This seems to work well - indeed the CopyFiles program in Hadoop (aka
distcp) follows this pattern to efficiently copy files between distributed filesystems:1. The input to each map task is a source file and a destination.
2. The map task is limited by its ability to copy the source to the destination (IO-bound).
3. The map output is used as a convenience to record files that were skipped.
4. There are no reducers.
Combined with Streaming this is a neat way to distribute your processing in any language. You do need a Hadoop cluster, it is true, but CPU-intensive jobs would happily co-exist with more traditional MapReduce jobs, which are typically fairly light on CPU usage.
Tuesday, 12 February 2008
Forgotten EC2 instances
I noticed today that I had an EC2 development cluster running that I hadn't shut down from a few days ago. It was only a couple of instances, but even so, it was annoying. Steve Loughran had a good idea for preventing this: have the cluster shut itself down if it detects you go offline - by using your chat presence. You'd probably want to build a bit of a delay into it to avoid losing work due to some network turbulence, but it would work nicely for short lived clusters which are brought up simply to do a bit of number crunching. Alternatively, and perhaps more lo-tech, the cluster could just email you every few hours to say "I'm still here!".
I wonder how many forgotten instances are running at Amazon at any one time. Is there a mass calling of ec2-terminate-instances every month end when the owners see their bills?
I wonder how many forgotten instances are running at Amazon at any one time. Is there a mass calling of ec2-terminate-instances every month end when the owners see their bills?
Friday, 1 February 2008
Apache Incubator Proposal for Thrift
There's a proposal for Thrift to go into the Apache Incubator. This seems to me to be a good move - there's increasing interest in Thrift - just look at the number of language bindings that have been contributed: Cocoa/Objective C, C++, C#, Erlang, Haskell, Java, OCaml, Perl, PHP, Python, Ruby, and Squeak at the last count. It's even fairly painless to compile on Mac OS X now, although it'd be nice to have a Java version of the compiler.
Also, there are some nice synergies with other Apache projects - it is already being used in HBase, and there are moves to make it easier to use in Hadoop Core as a serialization format (so MapReduce jobs can consume and produce Thrift-formatted data).
If the proposal is accepted it will be interesting to see what happens to Hadoop's own language-neutral record serialization package, Record I/O. The momentum is certainly with Thrift and discussions on the mailing list suggest that stuff will eventually be ported to use Thrift.
Also, there are some nice synergies with other Apache projects - it is already being used in HBase, and there are moves to make it easier to use in Hadoop Core as a serialization format (so MapReduce jobs can consume and produce Thrift-formatted data).
If the proposal is accepted it will be interesting to see what happens to Hadoop's own language-neutral record serialization package, Record I/O. The momentum is certainly with Thrift and discussions on the mailing list suggest that stuff will eventually be ported to use Thrift.
Wednesday, 30 January 2008
Hadoop and Log File Analysis
I've always thought that Hadoop is a great fit for analyzing log files (I even wrote an article about it). The big win is that you can write ad hoc MapReduce queries against huge datasets and get results in minutes or hours. So I was interested to read Stu Hood's recent post about using Hadoop to analyze email log data:
Can we take this further? It seems to me that there is a gap in the market for an open source web traffic analysis tool. Think Google Analytics where you can write your own queries. I wonder who's going to build such a thing?
Here at Mailtrust, Rackspace’s mail division, we are taking advantage of Hadoop to help us wrangle several hundred gigabytes of email log data that our mail servers generate each day. We’ve built a great tool for our support team that lets them search mail logs in order to troubleshoot problems for customers. Until recently, this log search and storage system was centered around a traditional relational database, which worked fine until the exponential growth in the volume of our dataset overcame what a single machine could cope with. The new logging backend we’ve developed based on Hadoop gives us virtually unlimited scalability.The best bit was when they wrote a MapReduce query to find the geographic distribution of their users.
This data was so useful that we’ve scheduled the MapReduce job to run monthly and we will be using this data to help us decide which Rackspace data centers to place new mail servers in as we grow.It's great when a technology has the ability to make such a positive contribution to your business. In Doug Cutting's words, it is "transformative".
Can we take this further? It seems to me that there is a gap in the market for an open source web traffic analysis tool. Think Google Analytics where you can write your own queries. I wonder who's going to build such a thing?
Wednesday, 16 January 2008
Hadoop is now an Apache Top Level Project
Doug Cutting just reported on the Hadoop lists that the Apache board voted this morning (US time) to make Hadoop a TLP. Until now it has been a Lucene subproject, which made sense when Hadoop was broken out from the Nutch codebase two years ago. Since then Hadoop has grown dramatically. This change will make it possible for a number of associated projects - such as HBase and Pig - to become Hadoop subprojects in their own right. (There are more details in the original discussion.)
Thanks for looking after us Lucene - it's been a great time so far and we'll keep in touch!
Thanks for looking after us Lucene - it's been a great time so far and we'll keep in touch!
Sunday, 13 January 2008
MapReduce, Map Reduce, Map/Reduce or Map-Reduce?
Although I've seen the other variants (and used some of them myself), Google call it "MapReduce", so that seems like the right thing to call it to me, since they invented it. The usage figures seem to back up this conclusion. "MapReduce" (no space) has 87,000 Google hits, while "Map Reduce" (with space) has only 50,200, and the latter includes "Map/Reduce" and "Map-Reduce" variants, since Google (and search engines in general) ignore punctuation.
In this age of case sensitivity and camel case one has to watch out for these things. In fact, I've only just realised that the Hadoop database is called "HBase", not "Hbase". The curse of wiki names. And the logo doesn't help either - it's all caps!
In this age of case sensitivity and camel case one has to watch out for these things. In fact, I've only just realised that the Hadoop database is called "HBase", not "Hbase". The curse of wiki names. And the logo doesn't help either - it's all caps!
Monday, 7 January 2008
Casual Large Scale Data Processing
I think Greg Linden hits the nail on the head when he says of MapReduce at Google:
What is so remarkable about this is how casual it makes large scale data processing. Anyone at Google can write a MapReduce program that uses hundreds or thousands of machines from their cluster. Anyone at Google can process terabytes of data. And they can get their results back in about 10 minutes, so they can iterate on it and try something else if they didn't get what they wanted the first time.I think this is a good way of looking at what Hadoop is trying to achieve - to make large scale data processing as natural as small scale data processing. Hadoop can provide infrastructure to do this, but there is also a need for open datasets that are MapReducable. Imagine if I could run a MapReduce program against Google's web crawl database, Amazon's sales data or Facebook's social graph.
Subscribe to:
Posts (Atom)